Електронні таблиці Excel часто містять випадаючі вікна для спрощення та / або стандартизації введення даних. Ці випадаючі списки створюються за допомогою функції перевірки даних, щоб визначити список допустимих записів.
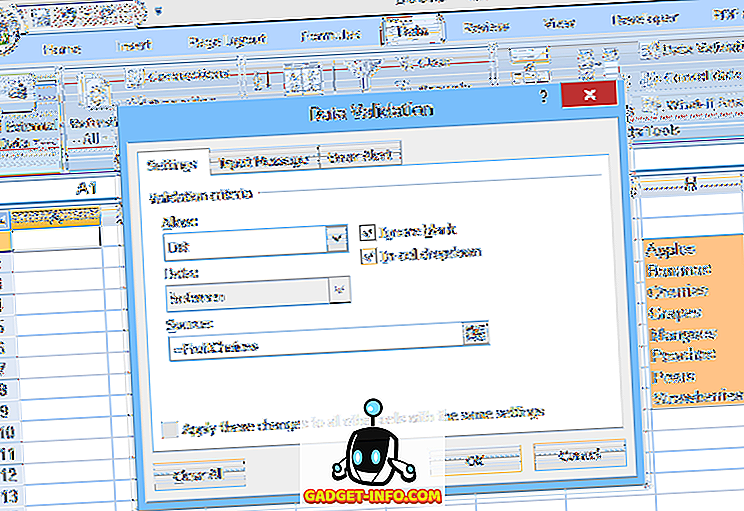
Щоб налаштувати простий випадаючий список, виберіть клітинку, де будуть введені дані, а потім клацніть Перевірка даних (на вкладці Дані ), виберіть Перевірка даних, виберіть Список (у розділі Дозволити :), а потім введіть елементи списку (розділені комами ) у полі Source : (див. рис. 1).
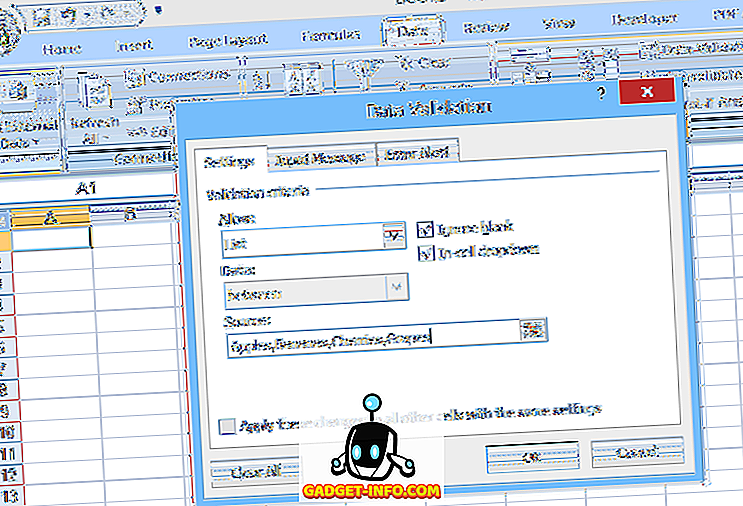
У цьому типі основного випадаючого списку список допустимих записів вказується в межах самої перевірки даних; тому, щоб внести зміни до списку, користувач повинен відкрити та відредагувати перевірку даних. Однак це може бути важко для недосвідчених користувачів або у випадках, коли список вибору є тривалим.
Іншим варіантом є розміщення списку в іменованому діапазоні в електронній таблиці, а потім вкажіть це ім'я діапазону (попередній з ознакою рівності) в полі Source : джерела даних (як показано на малюнку 2).
Цей другий спосіб полегшує редагування варіантів у списку, але додавання або видалення елементів може бути проблематичним. Оскільки названий діапазон (FruitChoices, у нашому прикладі) відноситься до фіксованого діапазону клітин ($ H $ 3: $ H $ 10, як показано), якщо до клітин H11 або нижче додано більше варіантів, вони не з'являться у спадному меню (оскільки ці комірки не входять до діапазону FruitChoices).
Так само, якщо, наприклад, записи "Груші та суниці" видаляються, вони більше не з'являтимуться у випадаючому списку, але замість цього у спадному списку будуть два "порожні" варіанти, оскільки у спадному списку все ще згадується весь діапазон FruitChoices, включаючи порожні клітинки H9 і H10.
З цих причин при використанні звичайного діапазону з іменем як джерела списку для випадаючого списку, сам діапазон має бути відредагований, щоб включити більше або менше комірок, якщо записи додано або видалено зі списку.
Рішення цієї проблеми полягає у використанні імені динамічного діапазону як джерела вибору випадаючого списку. Ім'я динамічного діапазону - це той, який автоматично розширюється (або стикається), щоб точно відповідати розміру блоку даних, оскільки записи додано або видалено. Для цього ви використовуєте формулу, а не фіксований діапазон адрес комірки, щоб визначити іменований діапазон.
Як встановити динамічний діапазон в Excel
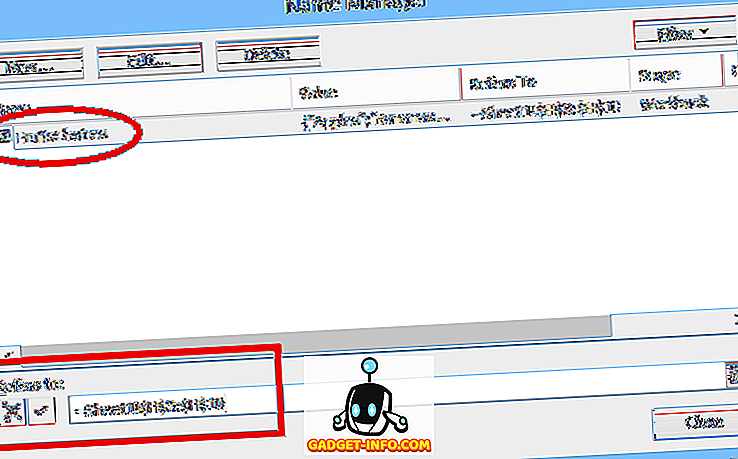
Нормальне (статичне) ім'я діапазону стосується певного діапазону осередків ($ H $ 3: $ H $ 10 у нашому прикладі, див. Нижче):
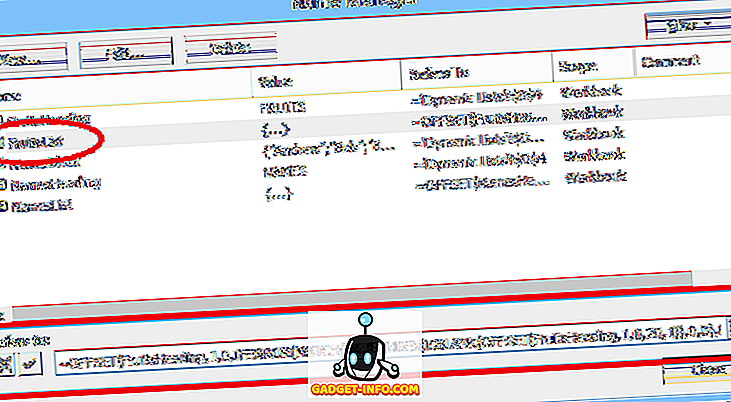
Але динамічний діапазон визначається за допомогою формули (див. Нижче, взято з окремої електронної таблиці, яка використовує імена динамічних діапазонів):
Перш ніж почати, переконайтеся, що завантажили наш прикладний файл Excel (макроси сортування були вимкнуті).
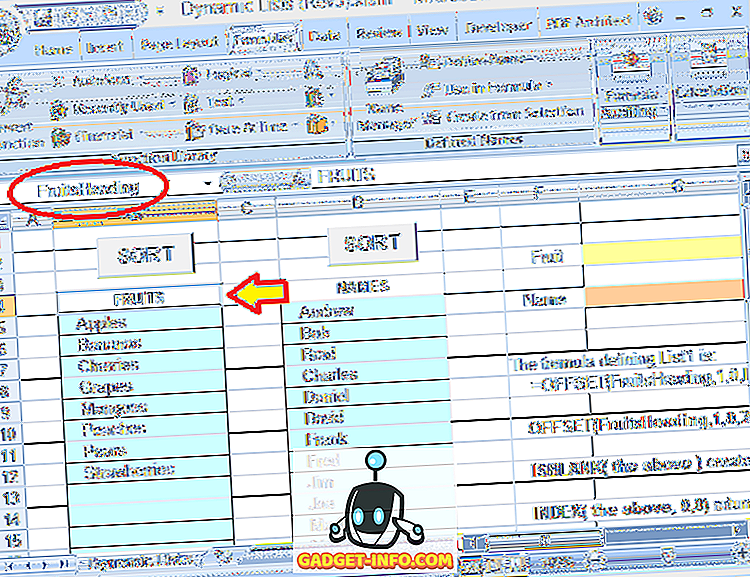
Давайте детально розглянемо цю формулу. Вибір для фруктів - це блок клітин безпосередньо під заголовком ( FRUITS ). Цим заголовком також присвоєно ім'я: FruitsHeading :
Уся формула, яка використовується для визначення динамічного діапазону для вибору фруктів:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH) (TRUE, INDEX (ISBLANK (OFFSET (Фрукти), 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading відноситься до заголовка, який є одним рядком над першим записом у списку. Число 20 (два рази у формулі) - це максимальний розмір (кількість рядків) для списку (його можна налаштувати за бажанням).
Зверніть увагу, що в цьому прикладі є лише 8 записів у списку, але також є порожні клітинки, під якими можна додати додаткові записи. Число 20 відноситься до всього блоку, де можуть бути зроблені записи, а не до фактичної кількості записів.
Тепер давайте розберемо формулу на частини (колірне кодування кожного фрагмента), щоб зрозуміти, як він працює:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH) (TRUE, INDEX (ISBLANK ( OFFSET (Фрукти), 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
"Самий внутрішній" шматок - OFFSET (FruitsHeading, 1, 0, 20, 1) . Це посилається на блок з 20 клітин (під клітиною FruitsHeading), де можуть бути введені варіанти. Ця функція OFFSET в основному говорить: Почніть з клітинки FruitsHeading, спустіться на 1 рядок і більше 0 стовпців, а потім виберіть область, яка довжиною 20 рядків і 1 колонку. Отже, це дає нам блок з 20 рядків, де вводяться вибори фруктів.
Наступною частиною формули є функція ISBLANK :
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH) (ІСТИНА, ІНДЕКС ( ISBLANK (вище), 0, 0), 0) -1, 20), 1)
Тут функція OFFSET (описана вище) була замінена на "вище" (щоб зробити речі простішими для читання). Але функція ISBLANK працює на 20-рядковому діапазоні осередків, які визначає функція OFFSET.
Після цього ISBLANK створює набір з 20 значень TRUE і FALSE, вказуючи, чи кожна з окремих осередків у 20-рядковому діапазоні, на яку посилається функція OFFSET, є порожньою (порожньою) чи ні. У цьому прикладі перші 8 значень у наборі будуть FALSE, оскільки перші 8 клітин не є порожніми, а останні 12 значення будуть TRUE.
Наступним фрагментом формули є функція INDEX:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (вище, 0, 0), 0) -1, 20), 1)
Знову ж таки, «вище» відноситься до функцій ISBLANK і OFFSET, описаних вище. Функція INDEX повертає масив, що містить 20 значень TRUE / FALSE, створених функцією ISBLANK.
INDEX, як правило, використовується для вибору певного значення (або діапазону значень) з блоку даних, вказавши певний рядок і стовпець (в межах цього блоку). Але встановлення рядків і стовпців до нуля (як це зроблено тут) призводить до того, що INDEX повертає масив, що містить весь блок даних.
Наступним фрагментом формули є функція MATCH:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, вище, 0) -1, 20), 1)
Функція MATCH повертає положення першого значення TRUE у масив, який повертається функцією INDEX. Оскільки перші 8 записів у списку не є порожніми, перші 8 значень в масиві будуть FALSE, а дев'яте значення буде TRUE (оскільки 9-й рядок в діапазоні порожній).
Таким чином, функція MATCH поверне значення 9 . У цьому випадку, однак, ми дійсно хочемо знати, скільки записів знаходиться в списку, тому формула віднімає 1 з значення MATCH (яке дає позицію останнього запису). Отже, в кінцевому рахунку, MATCH (TRUE, вище, 0) -1 повертає значення 8 .
Наступним фрагментом формули є функція IFERROR:
= OFFSET (ФруктиЗаголовок, 1, 0, IFERROR (вище, 20), 1)
Функція IFERROR повертає альтернативне значення, якщо перше вказане значення призводить до помилки. Ця функція включена, оскільки, якщо весь блок клітин (всі 20 рядків) заповнюється записами, функція MATCH поверне помилку.
Це пояснюється тим, що ми говоримо функції MATCH шукати перше значення TRUE (у масиві значень з функції ISBLANK), але якщо NONE з порожніх клітин, то весь масив буде заповнений значеннями FALSE. Якщо MATCH не може знайти цільове значення (TRUE) в масиві, який він шукає, він повертає помилку.
Отже, якщо весь список заповнений (і, отже, MATCH повертає помилку), функція IFERROR замість цього поверне значення 20 (знаючи, що повинно бути 20 записів у списку).
Нарешті, OFFSET (FruitsHeading, 1, 0, вище, 1) повертає діапазон, який ми насправді шукаємо: Почнемо з клітинки FruitsHeading, спускаємося вниз на 1 рядок і більше 0 стовпців, потім вибираємо область, яка, однак, багато строк у списку є записи (1 ширина). Отже, вся формула разом поверне діапазон, який містить тільки фактичні записи (до першої порожньої клітинки).
Використовуючи цю формулу для визначення діапазону, який є джерелом для випадаючого списку, ви можете вільно редагувати список (додавання або видалення записів, поки інші записи починаються з верхньої комірки і є суміжними), а випадаюче завжди відображатиме поточний (див. рис. 6).
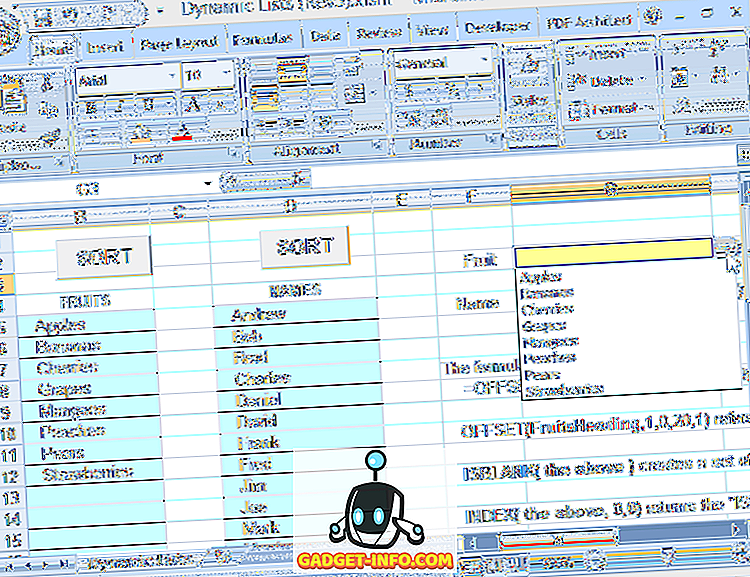
Файл прикладу (динамічні списки), який тут використовувався, включений і завантажується з цього веб-сайту. Однак макроси не працюють, тому що WordPress не любить книги Excel з макросами в них.
В якості альтернативи визначенню кількості рядків у блоці списку, блоку списку може бути присвоєно власне ім'я діапазону, яке потім може бути використано у зміненій формулі. У файлі прикладу другий список (Імена) використовує цей метод. Тут весь блок списку (під заголовком "NAMES", 40 рядків у файлі прикладу) присвоюється назва діапазону NameBlock . Альтернативна формула для визначення списку імен Names:
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH) (ІСТИНА, ІНДЕКС (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
де NamesBlock замінює OFFSET (FruitsHeading, 1, 0, 20, 1) і ROWS (NamesBlock) замінює 20 (кількість рядків) у попередній формулі.
Отже, для випадаючих списків, які можна легко редагувати (включаючи інших користувачів, які можуть бути недосвідченими), спробуйте використовувати імена динамічних діапазонів! І зверніть увагу, що, хоча ця стаття була сфокусована на випадаючих списках, імена динамічних діапазонів можна використовувати в будь-якому місці, де потрібно посилатися на діапазон або список, який може відрізнятися за розміром. Насолоджуйтесь!