Ширина смуги частот, що використовується в пам'яті UMA, обмежена, оскільки вона використовує один контролер пам'яті. Основним мотивом появи машин NUMA є підвищення доступної пропускної здатності до пам'яті за допомогою декількох контролерів пам'яті.
Діаграма порівняння
| Основа для порівняння | UMA | NUMA |
|---|---|---|
| Основний | Використовує один контролер пам'яті | Кілька контролерів пам'яті |
| Тип використовуваних автобусів | Одномісний, багаторазовий і поперечний. | Дерево і ієрархічне |
| Час доступу до пам'яті | Рівний | Зміни відповідно до відстані мікропроцесора. |
| Підходить для | Програми загального призначення та спільного використання часу | У реальному часі та критичних для часу додатків |
| Швидкість | Повільніше | Швидше |
| Пропускна здатність | Limited | Більше, ніж UMA. |
Визначення UMA
Система UMA (Uniform Memory Access) є архітектурою спільної пам'яті для мультипроцесорів. У цій моделі єдина пам'ять використовується і доступна всім процесорам, які представляють мультипроцесорну систему за допомогою мережі взаємоз'єднання. Кожен процесор має рівний час доступу до пам'яті (затримки) і швидкість доступу. Він може використовувати будь-який з одного шини, декількох шин або перемикач поперечини. Оскільки він забезпечує збалансований доступ до спільної пам'яті, він також відомий як SMP (Symmetric multiprocessor) .
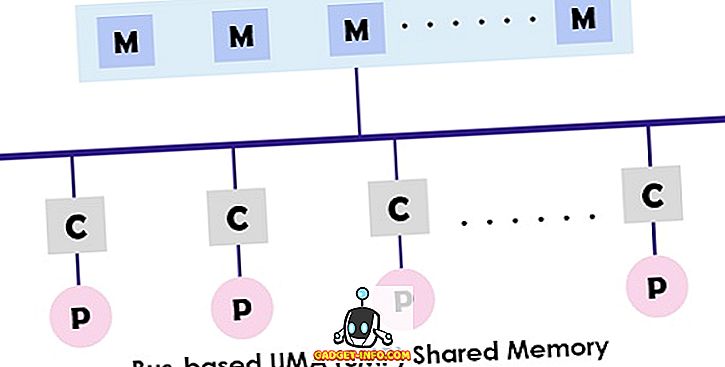
Типова конструкція SMP показана вище, де кожен процесор спочатку з'єднаний з кешем, після чого кеш пов'язаний з шиною. Нарешті шина підключена до пам'яті. Ця архітектура UMA зменшує конкуренцію для шини шляхом отримання інструкцій безпосередньо з окремого ізольованого кешу. Він також забезпечує рівну ймовірність для читання і запису до кожного процесора. Типовими прикладами моделі UMA є сервери Sun Starfire, альфа-сервер Compaq і серія HP v.
Визначення NUMA
NUMA (неоднорідний доступ до пам'яті) також є багатопроцесорною моделлю, в якій кожен процесор з'єднаний з виділеною пам'яттю. Однак ці невеликі частини пам'яті об'єднуються для створення єдиного адресного простору. Головне, щоб обміркувати тут, що на відміну від UMA, час доступу пам'яті залежить від відстані, де розташований процесор, що означає різний час доступу до пам'яті. Це дозволяє отримати доступ до будь-якого місця пам'яті за допомогою фізичної адреси.
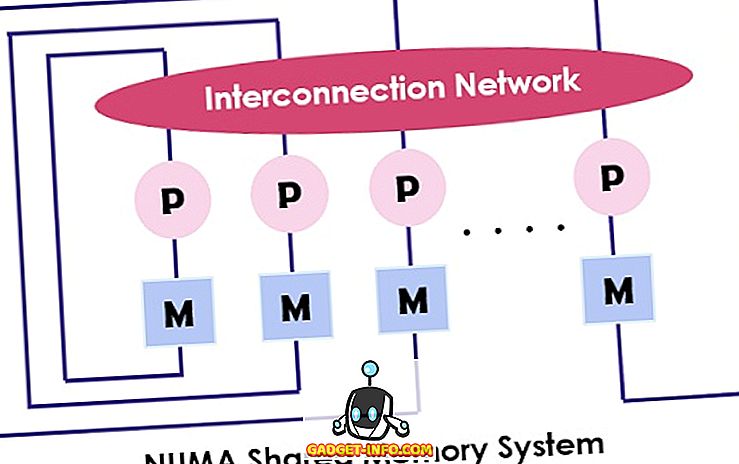
Як згадувалося вище, архітектура NUMA призначена для збільшення доступної смуги пропускання до пам'яті і для якої вона використовує кілька контролерів пам'яті. Вона поєднує в собі численні ядер машин в « вузли », де кожен ядро має контролер пам'яті. Для доступу до локальної пам'яті в машині NUMA ядро витягує пам'ять, керовану контролером пам'яті, своїм вузлом. Хоча для доступу до віддаленої пам'яті, яка обробляється іншим контролером пам'яті, ядро передає запит на пам'ять через посилання взаємозв'язку.
Архітектура NUMA використовує дерева і ієрархічні шинні мережі для з'єднання блоків пам'яті і процесорів. BBN, TC-2000, SGI Origin 3000, Cray - деякі з прикладів архітектури NUMA.
Основні відмінності між UMA та NUMA
- Модель UMA (спільна пам'ять) використовує один або два контролери пам'яті. На відміну від цього, NUMA може мати кілька контролерів пам'яті для доступу до пам'яті.
- В архітектурі UMA використовуються одиночні, множинні та ригельні шини. І навпаки, NUMA використовує ієрархічний і деревоподібний тип шин і мережеве підключення.
- У UMA час доступу до пам'яті для кожного процесора є однаковим, тоді як в NUMA час доступу до пам'яті змінюється по мірі зміни відстані пам'яті від процесора.
- Для пристроїв UMA підходять загальні та спільні програми. На відміну від цього, відповідним додатком для NUMA є в реальному часі і критично для часу.
- Паралельні системи на базі UMA працюють повільніше, ніж системи NUMA.
- Коли мова заходить про пропускну здатність UMA, мають обмежену пропускну здатність. Навпаки, NUMA має пропускну здатність більше, ніж UMA.
Висновок
Архітектура UMA забезпечує таку ж загальну затримку процесорам, які мають доступ до пам'яті. Це не дуже корисно, коли доступ до локальної пам'яті здійснюється, оскільки затримка буде однорідною. З іншого боку, в NUMA кожен процесор мав свою виділену пам'ять, що виключає затримку при доступі до локальної пам'яті. Час затримки змінюється як відстань між процесором і зміною пам'яті (тобто, Нерівномірний). Однак, NUMA покращила продуктивність в порівнянні з архітектурою UMA.